In this article we will discuss some key elements and concepts of Artificial Intelligence (AI). We will try to outline a brief history in order to highlight how its plot is woven from technical, social and cultural aspects that justify the claims – by the human communities in which these technologies are built and applied – to criticize and generally control its developments.
This claim, moreover, is useful to counterbalance both the narratives aimed at exaggerating the expectations that are generated around AI, and the accusations according to which these criticisms have the sole purpose of hindering/bureaucratizing free technological development – theses often advanced in a simplistic and highly self-interested manner.
In general, as has always been the case since we learned to live in a political and economic system in which it was deemed legitimate to leave the development and introduction of technologies into social spheres to so-called “free” market forces, we are now once again engaged in understanding some of the problematic issues that this cultural-philosophical approach entails.
Relationship between algorithms, programs and machines/computers
Algorithms AI is a technology made up of algorithms, or sets of automatable procedures (recipes) that contain elements and reasoning capable of developing products/functions. So let’s start with algorithms.
Generally speaking, to be effectively implemented, algorithms must be translated/detailed – in all their steps – into programs containing primitive instructions that can be understood and executed by people or machines, the agents that ultimately realize and make them actually functional (Kneusel 2023).

The interrelation between algorithms, programs and people/machines is necessary when we want to create – and also, in some way, “replicate”, in a more or less continuous cycle – the product or function described in it.
This scheme is ultimately at the heart of mechanization techniques – typical of the various industrial revolutions – or the implementation of automatic processes through machinery that free human beings from the slavery of work although, as the sociologist and historian of technology Lewis Mumford recalls, in our industrial and capitalist civilization this has always entailed a risk since “the tendency of automation is to subordinate human ends to the means originally created to serve them” (1954).
In the case of AI, this warning is even more precious since we want to create automated technologies – machines that perceive, reason, decide, etc. – also capable of embodying those human abilities considered, in the hierarchy of terrestrial life, among the highest and most distinctive for associated life of people.
The same relationship between algorithms, programs and workers/machines also highlights how the creation of such functional procedures has an ancient soul in which the final mechanical implementing subject, the computer, is only a latest innovation.

From this point of view, cultural scholar Ted Striphas is very instructive when he dedicates to the concept of algorithm and its inventor – the Persian mathematician of the 9th century AD, Muhammad ibn Musa al-Khwarizm, father of algebra, much cited but never investigated in this sense – a long study to understand the social origins of algorithmic culture, or the ancient human need to address complex questions, even moral ones, through mathematics/computation (2023).
An important clue to the changes that have occurred over time is that computation itself was expressed in ancient times through normal everyday language – only later was it caged and formalized in specific symbols that could be manipulated, and often understood, only by specialists.
So a human being conceives an algorithm and translates that algorithm into a sequence of steps (a program containing instructions) that is given as input to a company (workers) or to a machine – since the 1950s, to a special machine such as a computer – capable of executing the instructions that implement it. Note that the machine/computer does not understand what it is doing; it is simply executing, in its specific domain (made of logic and mathematics) a series of primitive instructions.
The declared aim of wanting to automate the most sophisticated intellectual capacities puts AI on a problematic level of attention given that its devices will replace or integrate human activities, creating a new existential ecology, new relational networks and, above all, new power structures.
Consider, to take one of the most popular themes, the possible reduction of jobs in sectors that were previously thought to be unscathed, such as the intellectual ones. With industrialization, automation has already greatly reduced human labor in the extractive and manufacturing sectors in most countries of the world. In these, it is the service sector that has so far proved to be a great reserve and a driver of employment thanks to the absorption of intellectual labor, so intertwined with the conception and development of transmission and information technologies (Information & Communication Technology) that have expanded the design, circulation and sale of goods thanks to these new techniques of symbolic processing and remote control (Beniger 1986).
And it is precisely the sector of services that is expected to see massive use of AI. Even if we remain within the liberal economic paradigms, this fact requires a new approach in the ways of redistributing the wealth of a production that knows or wants to do without the quality of human work, an approach that cannot ideologically repudiate innovative and socially supportive models in the face of the growing danger of the impossibility of peacefully coexisting with one another.
From this point of view, despite feeling obliged to talk about AI in every context, there is not a great echo of a political debate that advances specific proposals on the topic.
Birth of AI
To function, AI needs a computer. To be precise, the computer itself was born as the implementation of an algorithm that will prove capable of processing any other algorithm/calculation a human being can conceive (Wikipedia).
Designed by the brilliant English mathematician Alan Turing (1912-1954), it has been defined as the Turing machine. The abstract machine designed by Turing is innovative in that it detaches itself from the purpose of performing a particular physical activity – digging, collecting, moving, etc.
Really, it too is “a machine that performs a particular physical activity, that is, selecting or deselecting certain positions on a tape in a certain order. But it can be seen from another perspective, as a system that acts on information: a mark on the tape is in this sense information”. Philosophers christened it as a neo-mechanism.
For Turing, an infinity of this type of machines can exist because they “are distinguished by their table of instructions, which tells them, at each stage, which of the simple operations available to them they must apply… Combined with the Turing-Church thesis, this result has the consequence that every calculation that a man is capable of carrying out can be carried out by a Turing machine” (Adler 2023).
At the same time, conceptually the computer and AI were born together if we think of the famous article published in 1950, and entitled Computing Machinery and Intelligence, in which Turing himself wondered if these machines could think, going so far as to hypothesize that one day “they will be able to equal men in all purely intellectual fields”. The same scientist developed a test to evaluate, by comparing their interactive dialogue capabilities, whether the speaking subject was a human being or a computer – the so-called Turing test.

The term “artificial intelligence” was instead coined in the 1950s by the famous computer scientist John McCarthy (1927-2011). The core of his definition – AI is a technique that attempts to convince a machine, since the 20th century generally a computer, to behave in ways that humans believe to be intelligent – clearly reveals how it is an experimental science, or research based on attempts at development, assembly and simulation that draws inspiration, first and foremost, from computer science and engineering knowledge.
Dependent in a fatal way on the success of its experiments – any funder, public or private, must justify its outlays, either with respect to the priorities of intervention for public spending, or in terms of return on investment – we will see how the history of AI has been characterized by periods of large funding (summers) followed, following some failure to meet the promised expectations, by years marked by a scarcity of funds (winters).
Keeping the hype constantly high and speaking hyperbolically about every aspect of it – even the supposed dystopian implications, so that their drifts can eventually be controlled – is part of an overall strategy that serves to not let the tension drop and in any case be remembered – by the various decision makers – as an important theme in which it is necessary to invest.
Human in the loop: different types of algorithms and the role of the human programmer
The different possibilities of making a machine intelligent
Since its birth, AI has thought of different ways to model intelligence – namely algorithms and this is why, generally, we see representations in which the field of AI is represented in at least two subfields – symbolic AI and subsymbolic or connectionist AI (machine learning and deep learning are part of the latter).
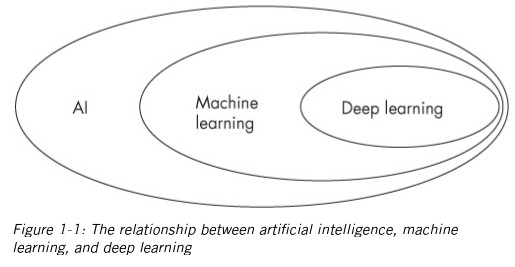
Symbolic AI and Subsymbolic AI (Connectionism)
With symbolic AI we try to model intelligence (the algorithm) by programming machines through symbols and logical statements or associations. We use symbols as elements of thought and language to develop and transfer reasoning and this is practically what every software programmer does when programming computers with the different programming languages invented from generation to generation (Assembler, Pascal, Fortran, C, Lisp, etc.).
Symbolic AI assumes that intelligence can be achieved in the abstract and does not worry about having to simulate a substrate that resembles a human brain to achieve it. In computer programming terms, this is a top-down approach: you start with a high-level analysis of activities and then break that activity down into increasingly smaller parts.
The symbolic AI trend has had an undoubted success in expert systems – systems that incorporate a vast knowledge base organized and used to manage a specific area of action – tempered by the fact that much of human knowledge is tacit/embodied, and therefore impossible to explain/codify symbolically.
With connectionist/subsymbolic AI, you try to model intelligence (the algorithm) by building networks of simpler components. Connectionists follow the evolutionary development of the brain: intelligence (however defined) emerges from the capture of small meaningful elements, similar to what human neurons, understood as simple processors but organized in complex networks, can do with our minds.
In terms of computer programming we have a bottom-up approach: we start with smaller parts and combine them together. We can see that human mind embodies both approaches (deductivism and inductivism).
Algorithm construction in AI
Symbolic AI

In symbolic AI, a programmer, as with all traditional algorithms that have populated computers since the 1950s, establishes the instructions in advance, having full knowledge of how to articulate the algorithm in the machine. In computer programming terms, we implement the algorithm we want by instructing the computer step by step.
Subsymbolic AI (machine learning, deep learning)

In connectionist AI, on the other hand, the algorithm itself “learns” instructions through “training data.” For example, no one tells this type of AI algorithm how to classify credit card transactions. Instead, the algorithm analyzes many examples from each of the two categories (fraudulent or non-fraudulent) and finds a pattern to distinguish one from the other.
Here the role of the programmer is not to tell the algorithm what to do. It is to tell the algorithm how to learn what to do, using the data available and the rules of probability (Polson, Scott 201).
The Rise of Subsymbolic AI and Neural Networks
The Principles of Subsymbolic AI

In 1957, Frank Rosenblatt (1928 –1971) of Cornell University created the Mark I Perceptron, widely recognized as the first application of neural networks. Rosenblatt is a psychologist with broad scientific interests and his idea is to exploit the processing capacity of neurons in the human brain by replicating their functions mathematically with the so-called perceptron.
As we know in biology, the neuron is a cell body to which energy arrives through incoming filaments (dendrites). When this energy reaches a certain threshold – in relation to the function on which it is shaped – the neuron is said to “switch on” in turn relaunching a certain outgoing energy on another filament (axon) that distributes it to the other connected cells.
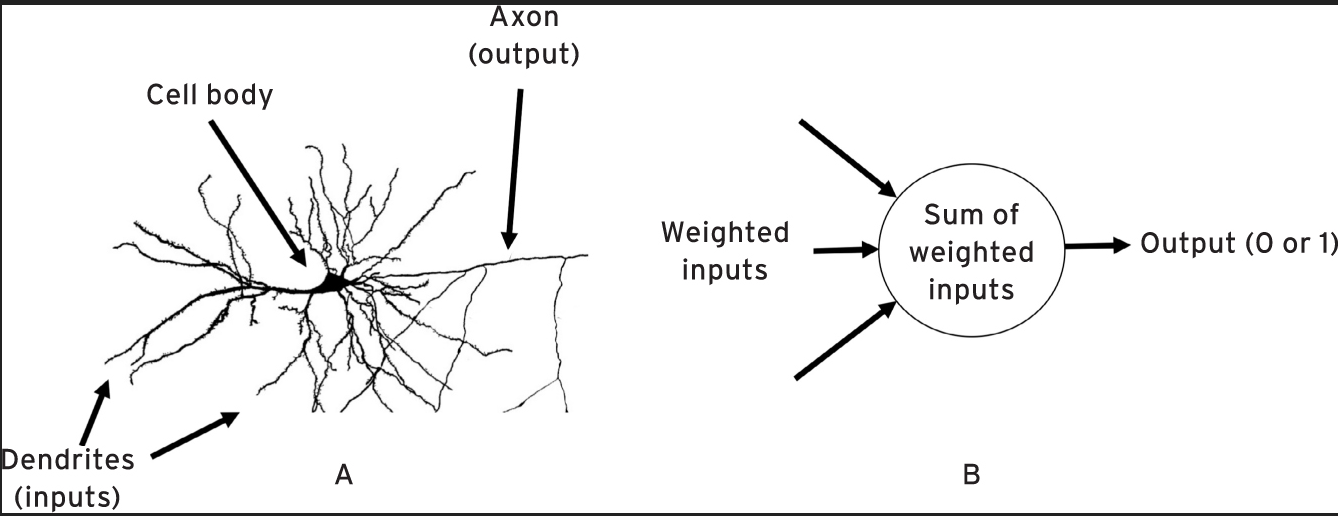
Figure 2. a) A brain neuron; b) a simple perceptron
The Rosenblatt perceptron is a mathematical function that collects weighted inputs to produce an output (zero or one). The inputs are said to be weighted because they interpolate the input values with parameters that allow the perceptron to “turn on” only when the assigned task has been achieved, thus releasing the expected value (zero or one, or a number between 0 and 1 that represents its probability) as an output. As we will see, the adjustment of those parameters is the purpose of training the machine.
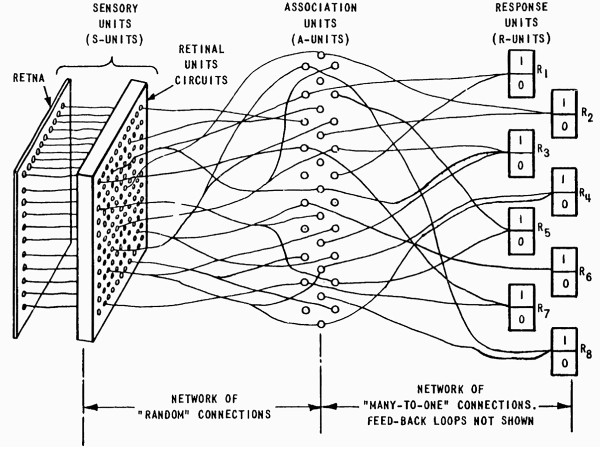
The Perceptron used a 20×20 pixel digitized television image as input, which was then passed through a “random” set of connections to a set of association units that led to a response unit.
In short, a perceptron is a simple program that makes a yes-or-no (1 or zero) decision based on whether the sum of its weighted inputs matches a threshold value. Inspired by networks of neurons in the brain, Rosenblatt proposed that networks of perceptrons could perform tasks, such as recognizing faces and objects.

Rosenblatt was successful in making people recognize images, specifically handwritten numbers. Let’s explain the experiment in more detail (Mitchell 2000).
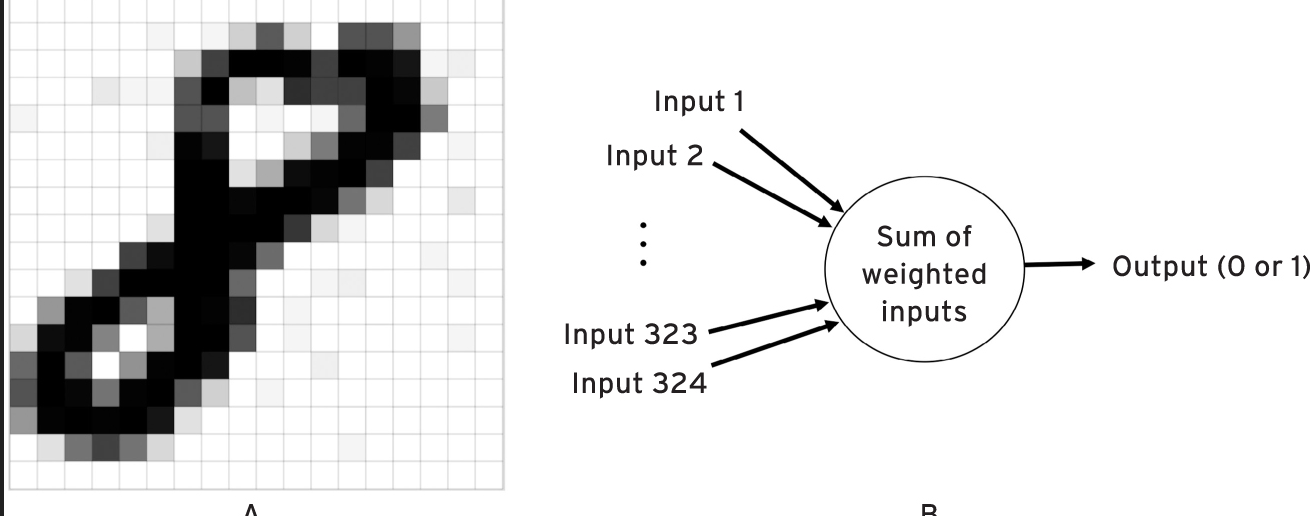
In this case the perceptron has 324 inputs (i.e. 18 × 18), each of which corresponds to a pixel of the 18 × 18 grid. Given a certain image each input of the perceptron is set according to the intensity of the corresponding pixel. Each input has its own weighting value (not shown in the figure).
How the “neuron” works
The “neuron” is supposed to process certain characteristics of an “object” to give us an output that leads to a class label – x, w, b are numbers, h is an algorithmic activation function of the so-called “neuron” that produces the output number.
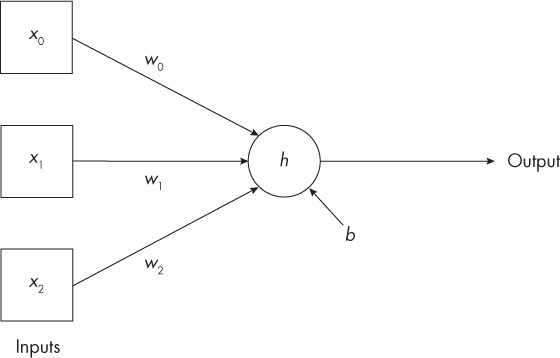
( x0, x1, x2) feature vector of the “object”
This minimal neural network (a neuron) sees as input an object described by a vector (set of numbers) consisting of three features (x0, x1, x2). The most commonly used activation function (h) is the REctified Linear Unit (ReLU) – and it is a question: is the input (the sum of the inputs multiplied by the individual weights w0, w1, w2, plus the bias b associated to neuron) less than zero? If so, the output is zero; otherwise, it is whatever the input is.
The neuron works like this:
1) Multiply each input value, x0, x1, and x2, by its associated weight, w0, w1, and w2;
2) Add all the products from step 1) together with the bias value, b. This produces a single number;
3) It feeds the single number to h, the activation function, to produce the output, also a single number.
As Kneusel (2023) affirms, virtually all the fantastic results of current AI – identifying dog breeds, driving a car, or translating from French to English – are due to sets of this primitive construct (the so-called model)!!
The complexity of neural networks
Obviously, to function adequately on complex problems, neural networks must be formed by more neurons, but with their increase, the parameters (weights and biases) necessary for their optimization inevitably grow, that is, for the definition of the right “switch-on” thresholds to be able to say that they satisfy the function for which they are designed.
Let’s consider simple neural models (2, 3, 8 nodes). How many numerical parameters (weights and biases) are involved in the various models?
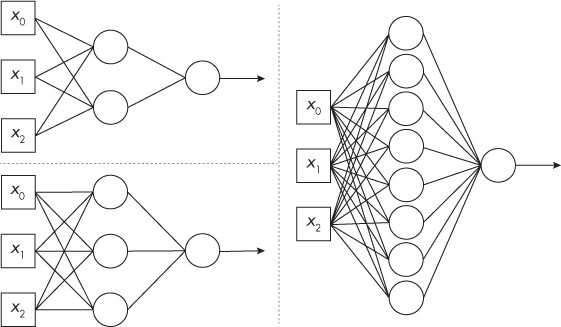
We need a weight for each line (except for the output arrow) and a bias value for each node. So: 1) for 2-nodes: 8 weights and 3 bias values; 2) for 3-nodes: 12 weights and 4 biases; 3) for 8-nodes: 32 weights and 9 bias values.
Neural Networks of the 21st Century
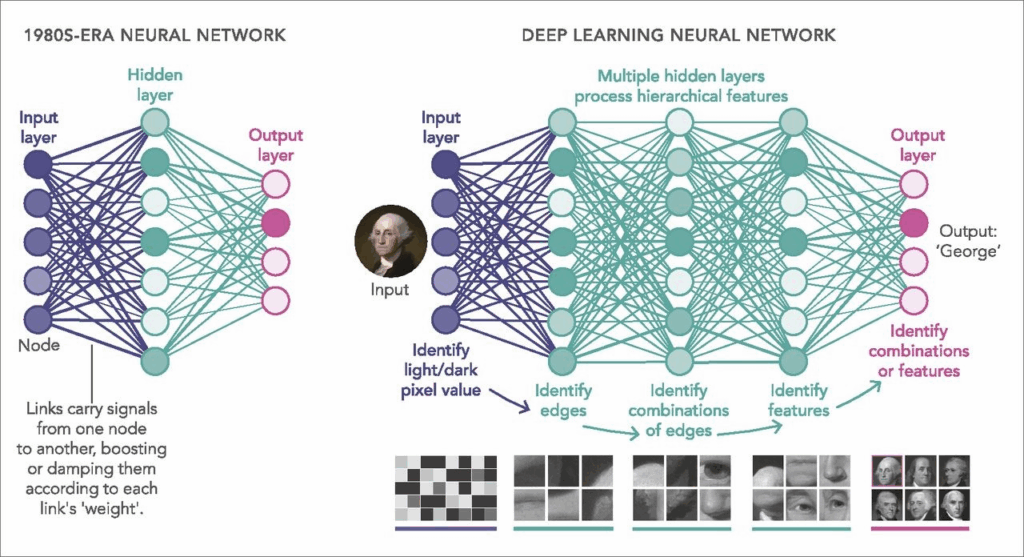
Neural network architectures have developed over time thanks above all to the increased performance of computers in terms of memory and computing power, so much so that the now famous Large Language Model (LLM) AI models are full of hidden layers of nodes, so that, for example, ChatGPT 3 and ChatGPT 4 work with neural architectures and a number of nodes that require a quantity of parameters (weights and biases) of, respectively, 175 billion and 1.7 trillion!!
What do you see of a trained model/algorithm?
At this point there are some questions that are legitimate to ask about the possibility of understanding, with respect to the type of algorithm defined (symbolic/connectionist), what are the logics that govern the quality of the answers provided by the models – people who find themselves having to receive answers from AI systems for legal and judicial questions, to have funding disbursements, to overcome hiring phases, to have health benefits, etc. should have explanations about it, and not have to settle for the good faith of the AI.
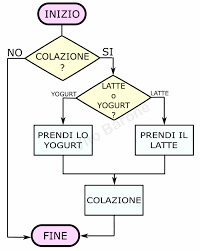
If you want to examine a symbolic algorithm, you can force the company that created it to show the source codes of the applications. In the open source software paradigm, this is not necessary since the software is “open” by definition to public examination – we are in an open science perspective, and therefore of common good, and the source codes are readable also to make improvement by others possible.
However, even if it were proprietary software, in case of need a public authority has the power to request and obtain it. In this case, the potential IT expert would have no difficulty in reconstructing the logical flow – in technical terms, the flow chart of the reasoning – that the program instructions have drawn.
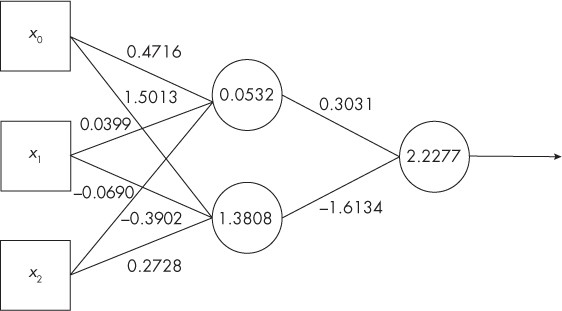
Let’s take instead the case of a subsymbolic algorithm, for example this simple neural model with a hidden layer of 2 nodes with which its creator (Kneusel 2023) manages to distinguish, with a fair probability of guessing, two qualities of different vines by providing as input 3 typical descriptive parameters for each of them.
Even when the creator is forced to reveal his structure – and here we are faced with an ultra-simple model, with only a dozen, and not billions, of parameters! – he can only show the final setting value of the weights and biases with which the model works – and for the view of such parameters in this type of algorithm we appropriately speak of open weight.
If the model responds in an inane way – so-called hallucinations – there is no way to understand why it did so. And often the human operators themselves who worked on the model cannot explain the reasons why it is able to acquire particular abilities (Mitchell 2000).
As you can imagine, we are in a black box situation in which, at least for the part of algorithms built with neural networks, it is not possible to explain to others its operating logic – when we talk about explainable AI we are asking to resolve precisely this type of limitation.
The Conditions for Machine Learning: Big Data and Computing Power
The training algorithm in machine learning
A machine learning model is a black box that takes an input, usually a collection of numbers (the vectors that describe the “object” through its specific characteristics) and produces an output, usually a label such as “bicycle” or “car”, or a continuous value such as the probability of being a “car”.
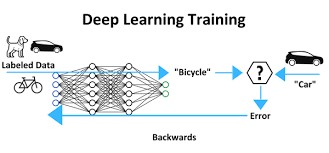
The model has parameters that control its output. Conditioning a model, known as training, tries to set the parameters so that it produces the correct output for a given input.
Training means that we have a collection of inputs and outputs that the model should produce when given those inputs. Why do we want the model to give us an output that we already have?
The answer is that, at some point in the future, we will have inputs for which we do not already have the output. In fact, the whole point is to create a model to use with unknown inputs and to believe the model when it gives us an output.
Training uses the collection of known inputs and outputs to adjust the model’s parameters to minimize errors. If we can do this, we will start to believe the model’s outputs when given new, unknown inputs.
So, here is the machine learning algorithm:
1) Collect a training dataset consisting of a collection of inputs to the model and the outputs;
2) Select the type of model we want to train;
3) Train the model by presenting the training inputs and adjusting the model parameters when it gets the outputs wrong;
4) Repeat step 3) until we are satisfied with the model’s performance;
5) Use the now trained model to produce outputs for new unknown inputs.
The Perceptron’s Short-lived Success
In 1957, Frank Rosenblatt’s Mark I Perceptron, working with USA Naval Research, was met with enthusiasm:

The Navy revealed the embryo of an electronic computer today
that it expects will be able to walk, talk, see, write, reproduce itself
and be conscious of its existence… Later perceptrons will be able to
recognize people and call out their names and instantly translate
speech in one language to speech and writing in another language,
it was predicted(New York Times 1958).
Apparently, we were 60 years ahead of our time!

Optimism and its funding are followed by pessimism. Training neural networks and similar methods to solve real-world problems was sometimes a slow and often ineffective process, due to the limited amount of data (also digitized and labeled) and computing power available at the time.
What makes subsymbolic AI possible now?
60 years have passed and many things have changed: just think about how we have now infrastructured our lives, so immersed in computing and the infosphere. Two major themes dominate in explaining the change in conditions.
Computer Speed
In 1945, the Electronic Numerical Integrator and Computer (ENIAC), the most powerful computer in the world, had a processing capacity, in terms of millions of instructions per second (MIPS), of 0.00289, about 3,000 instructions per second. In 1980, the personal computer reached 0.43 MIPS, about 500,000 instructions per second. In 2023, a medium-capacity personal computer with an Intel i7-4790 CPU, 130,000 MIPS – 300,000 times faster than the PC of the 80s, 45 million times faster than the ENIAC.
However, it is with the addition of the Graphic Processor Units (GPU) to the common Central Processor Unit (CPU) that we have a further and incredible increase in performance if we consider that the NVIDIA A100 GPU reaches 312 teraflops (TFLOPS), or 312,000,000 MIPS: 730 million times faster than a PC from the 80s and 110 billion times faster than the ENIAC.
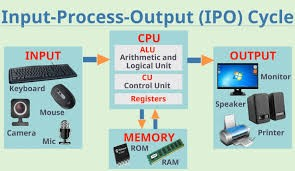
To be more precise, the classic computer architecture includes at least one CPU, and this works sequentially by executing one instruction after another.
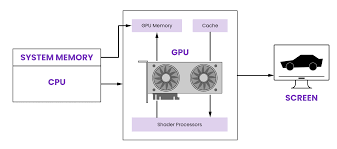
Graphics processing units (GPUs) were added when it was necessary to both improve user interfaces and handle the fast fruition of images – think of video games – making it easier to process video rendering.
GPUs were developed to support fast graphics – they can simultaneously perform the same operation, such as “multiply by 2”, on hundreds or thousands of memory locations (read: pixels). If a CPU wants to multiply a thousand memory locations by 2, it must multiply the first, the second, the third and so on in sequence.
GPUs, as we now know, are the necessary ingredient to also support neural network calculations as they make themselves available to programmers to speed up the disproportionate amount of operations that the billions of parameters of the models require, both in the training phase and in the inference phases (when they provide the answers to our prompts, in the case of LLMs).
A thorny and collateral issue to this enormous computational effort is that of energy consumption and environmental conditioning of these devices that require resources (production of electricity and cooling water) that are putting the sustainability of the common structures of civil installations into crisis (World Economic Forum 2025).
However, to get a sense of how much computing power has grown, consider the fact that in 1951 the Alfa Romeo 6C traveled at 180 kilometers per hour. If cars had followed the same exponential growth as computers, today it would travel at eight million times the speed of light! (Polson, Scott 2018).
Big Data: high availability of digitalized data
The Library of Congress, the largest library in the world, occupies 10 terabytes of memory, but in 2013 alone, the four largest technology companies – Google, Apple, Facebook and Amazon – collected data for an amount 120,000 times greater. In 2017, more than 300 hours of video were uploaded to YouTube every minute, and more than 100 million images were uploaded to Instagram every day.
We know that neural models learn from data; The more the better, because more data means a better representation of what the model will encounter when it is used. Without large data sets, and data that already has its labels associated with it, deep learning cannot learn.
Big data and the chaotic reality of algorithmic culture
The chaotic reality of algorithmic culture is the title of the talk that the American digital media scholar danah boyd dedicated in 2018 to the social context in which people operate since they have had the internet infosphere as their operating system for life.
Today we know that in order to participate in this new gold rush that the development of AI applications seems to be – which has become a billion-dollar industry that has become geopolitically strategic – you need to have extraordinary computing capacity and, above all, the ability to operate with big data.
Computing capacity, to tell the truth, can also be purchased from cloud service providers. If you have the capital, it is therefore possible to overcome this limit, unless you run into some political block because you are a company from a certain region of the world. The United States has restrictive technological policies, for example, towards China to defend its advantage in AI. Being the nation that has the main producer of GPU cards (Nvidia) and the most important cloud providers, it commercially allows only limited agreements in this specific sector.
The obsession with big data
The problem of big data, on the other hand, is, in general, much more limiting. To operate in AI – unless you want to develop niche applications – any small or medium-sized business must be able to count on the large amounts of data needed to train neural networks and these can only be generated on an “internet” scale, a scale of action and opportunities that we know has long been the preserve of a few big tech companies summarized by the acronym GAFAM (Google, Amazon, Facebook, Apple, Microsoft) or by Asian companies such as Alibaba, Tencent, Baidu, etc.
Boyd’s talk is dedicated precisely to the obsession that has been generated, by high-tech companies, towards big data.
In general, online companies’ obsession with data has many reasons. One is the desire to interface with propriety and effectiveness with the people who turn to their services to win them over indefinitely – speed and quality of interaction are a must for these environments and the accumulated data on events surrounds an operational framework useful for coordinating them. Another, which remains in line with the first, is to have the ammunition to fuel and build increasingly sophisticated predictive algorithms, to remain leaders in the sector and to design and build new tools and products. In short, without big data – volumes of enormous and renewable data, variously combined to cover all cases – it is not possible to build efficient models and innovate with the different declinations of AI algorithms.
But this way of building applications through training on data extracted and accumulated online also has a worrying underlying implication, at a cultural and social level, for at least two reasons. The first is that inertial functions are designed because they are shaped on past patterns, fixing and perpetuating conditions that reflect certain value and power structures, imposing them indiscriminately on everyone given the viral and global nature of digital services. The second is that great trust is placed in the quality and representativeness of the data thus generated.
The social origin of data
When we talk about big data we are talking about people who now carry out a significant part of their activities in the infosphere. Digital data therefore has a social dimension and if connectionist AI is trained on such data we have a lot of problems to deal with.
The scholar is very critical of this idea of considering data as the holy grail for solving problems through AI that we often know are intractable for the simple fact that we have contrasting opinions on them. For example, if in the field of medicine everyone agrees on having better treatments, on the concept of criminal justice there are very different opinions, sometimes incompatible – should we above all punish or recover people who make mistakes? It therefore becomes clear why the examples to push AI developments often recall the benefits brought in areas on which there is unanimity of views even though its applications and methodologies are applied transversally to all social contexts.
But the most powerful underlying criticism concerns the quality of digital data and its open nature to manipulation/interpretation – data must always be treated, or as Boyd says, “well cooked” to be usable.
There are problems at every level, starting from their collection, a real Wild West that AI, with its hunger for data, has exacerbated by literally “stealing” everything it finds on its way on the Internet without asking permission from the legitimate owners – the trend is the usual, and even worsened “do not ask permission in advance and if anything apologize if discovered”.
For a fair relationship between companies and people, informed choice should be the rule, extortion techniques an evil to be avoided, and the same should apply to the acquisition, and then the use, of data obtained through indirect circumstances – for boyd, this is the most popular type of collection, facilitated by the little concern that people themselves reserve for the issue, despite the fact that personal data is neither more nor less than their “DNA”.
Data quality
Neural software is therefore trained on statistical bases but we know the difficulties there are in having data samples that are truly representative of a certain distribution – and the problems remain even when there is the hope that a massive collection (on an internet scale) will solve it by incorporating an enormous amount of examples.
Digital data is in fact produced in the (chaotic) dynamics of interaction of digital environments where, among other things, it is common to find absences on unpopular topics – the so-called “data vacuum” – a fact that creates opportunities for others to insert distortions or hacks (Google bombing) on the “missing” topic in order to undermine its meaning or bring followers to their own theses.
Furthermore, data can be over- or under-represented for certain categories, generating or amplifying prejudices. Not to mention the people who purposely play with algorithmic systems to exploit their flaws by putting data online that is meaningless outside of this “fraudulent” context.
The dangers of new authoritarianisms
The talk is from 2018 but it does not seem to have lost its critical shine if we think about the scenario we are experiencing regarding the state of online information with the development of the latest generative AI algorithms, capable of creating – on text inputs suggested by users – realistic texts and videos on imaginary facts, cloning among other things the voices and bodies of real people. The references to boyd’s ethical themes through the figure of Hannah Arendt seem even more illuminating in the face of new authoritarian/technocratic dangers – as the historian and philosopher as well as critic of the strong powers wrote, “the ideal subject of the totalitarian regime is not the convinced Nazi or the convinced communist, but the individual for whom the distinction between reality and fiction, between true and false no longer exists” (1954).
Shock Absorbers and Moral Sponges
Finally, boyd reminds us of the constant danger we face as creators of socio-technical systems, namely that of releasing automated systems in which humans have only a figurative role, functioning as a moral crample zone – the definition is due to the scholar and expert on the relationship between data and society Madeleine Elish (2019).
The crample zone is that part of a car built to absorb shocks. For Madeleine Elish, we are in the presence of a moral crample zone whenever a human being is kept in the context of the functioning of a mechanism (human in the loop) as a reassuring subject despite knowing that their possible intervention in the event of a failure is highly problematic given the sophistication and automation of the system and the continuous functional demotion that the human operator experiences in it.
When critical failures occur, the human actor will probably have difficulty resolving the impasse and his role will only be to represent a “moral sponge” that will have to absorb the resentment of the community, together with all our hypocritical social irresponsibility.
References
Andler, D., 2023, Intelligence artificielle, intelligence humaine: la double énigme, Paris, Gallimard; trad. it. Il duplice enigma. Intelligenza artificiale e intelligenza umana, Torino, Einaudi 2024.
Arendt, H., 1954, Origins Of Totalitarianism, London, Penguin Classics 2017.
Beniger, J. R., 1986, The Control Revolution: Technological and Economic Origins of the Information Society, Harvard, Harvard University Press.
boyd, d., “The messy reality of Algorithmic Culture”, youtube.
Kneusel, R. T., 2023, How AI Works: From Sorcery to Science, S. Francisco, No Starch Press.
Mitchell, M., 2000, Artificial Intelligence.: A guide for thinking Humans, London, Picador Paper.
Mumford, L., 1954, In the Name of Sanity, New York, Harcourt, Brace, and Company; trad. it. In nome della ragione, Torino, Edizione comunità, 1959.
New York Times, 1958, NEW NAVY DEVICE LEARNS BY DOING; Psychologist Shows Embryo of Computer Designed to Read and Grow Wiser, July 8.
Polson, N., Scott, J., 2018, AIQ: How People and Machines Are Smarter Together, NY, St. Martin’s Press.
Striphas, T, 2023, Algorithmic Culture before the Internet, New York, Columbia University Press.
Turing, A., 1950, “Computing Machinery and Intelligence“, in Mind, New Series, Vol. 59, No. 236 (Oct.), pp. 433-460, Oxford University Press on behalf of the Mind Association.
Wikipedia, Turing Machine.
World Economic Forum, 2025, AI’s energy dilemma: Challenges, opportunities, and a path forward.