Limiti, imprese e responsabilità dei software culturali
Una recente campagna pubblicitaria promossa dalle Nazioni Unite — creata per attirare l’attenzione sulla prevalenza nel mondo delle opinioni sessiste e discriminatorie riguardo al genere femminile — è stata ideata sulle funzioni di ricerca di Google.



Più precisamente, essa ha sfruttato il motore introducendo un accenno di parole del tipo “women should …” per mostrare poi i suggerimenti offerti dalla funzione predittiva per ultimare i termini della ricerca.
L’algoritmo, che dovrebbe tenere conto sia delle ricerche più frequenti fatte dall’utenza sia delle combinazioni testuali riconosciute in quell’oceano di contenuti raccolti sulla rete, ha così portato alla superficie quanto di stereotipato sul tema possa circolare.
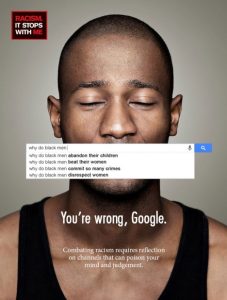
Nelle immagini della campagna le risposte diventano allora una sorta di bavaglio che silenzia la vera voce e personalità delle donne. Il successo della iniziativa (credits: Memac Ogilvy & Mather Dubai) nel rivelare i pregiudizi in maniera così incisiva e stridentemente attuale, in considerazione della nostra condizione post-moderna che si suppone così potentemente supportata in termini di tecnologie del pensiero, si può misurare con il dibattito aperto su twitter seguendo l’hashtag: #womenshould, ma anche dalle successive imitazioni, come quella sul razzismo con l’iniziativa australiana Racism. It Stops With Me.


Sull’importanza fondante del linguaggio per la strutturazione dell’essere umano nel suo processo di interazione con l’ambiente, e dunque non solo a livello simbolico, culturale ed etnico, ci siamo soffermati a lungo su questo spazio. Tra le altre cose, rilevavamo allora come
l’essere parlante si trova così a ricevere, unico tra le diverse specie, un’effettualità fatta di discorso, generato come chi è “parlato” ancora prima di essere parlante.
La preoccupazione su quanto lasciamo di costituito/parlato è dunque ben giustificabile di fronte all’avvento di queste nuove protesi di mediazione che, a differenza delle precedenti, intervengono prima o comunque nello stesso momento in cui proviamo a formulare un pensiero.
Come nota la studiosa svizzera Anna Jobin, particolarmente attratta dai fenomeni sociali che si dispiegano sulla spinta delle nuove tecnologie dell’online (just-in-time-sociology), tra i risvolti vi è la possibilità di essere subito incanalati, al di là delle nostre intenzioni, lungo le vie suggerite. E in ciò vi è un doppio rischio: attribuirvi subito veradicità — o comunque pensare che siano i concetti più accreditati — ma anche, in qualche modo, continuare a contribuire nel rafforzamento degli stereotipi.
D’altro canto, i meccanismi su cui si basa l’algoritmo non sono mai ben spiegati da Google, che avrebbe inoltre difficoltà a smentire il fatto che in alcuni paesi il suo codice debba lavorare insieme a quello censorio di alcuni stati particolarmente dediti al controllo delle libere pratiche di conoscenza ed espressione delle proprie popolazioni.
Google in qualche modo si trincera dietro l’oggettività dell’algoritmo, ma ciò può esimerci dal cercare responsabilmente delle soluzioni?
Se noi, come società, non vogliamo che gli stereotipi negativi (che riguardino generi, razze, abilità o qualunque altra categoria discriminatoria) prevalgano nella funzione di autocompletamento di Google, di chi è la responsabilità? Delle persone che per prime hanno formulato le richieste in maniera stereotipata? Delle persone che si sono succedute? Oppure di quelle che vi si sono adeguate nonostante avessero delle intenzioni iniziali diverse? E che ne è di Google stessa? … Ovviamente, gli algoritmi implicano automazione e l’alfabetizzazione digitale ci aiuta a comprenderne i processi … e tuttavia, gli algoritmi vanno oltre le problematiche tecnologiche: essi coinvolgono non solo l’automazione delle analisi dei dati ma anche un determinato processo decisionale (Jobin, 2013).
Bando dunque alle prese di posizioni dicotomiche tra intenzionalità o completa innocenza, e ampia apertura alla complessità della tematica anche perché, dice la Jobin, chi comanda quando al comando ci sono gli algoritmi ?
Dopo le vicende infinite dello spionaggio messo in atto dalla NSA statunitense, che ha utilizzato internet in lungo e in largo per sgraffignare bellamente ogni sorta di dati in ogni genere di applicazioni grazie a tecnologie automatizzabili — e dunque da qualcuno automatizzate — il tema della responsabilità etica sta facendo capolino anche nei circuiti ingegneristici.
La pervasività delle applicazioni software negli ambiti della quotidianità di vita di miliardi di persone inizia a richiedere, così come è per gli impatti delle applicazioni mediche o legali, oltre che una certosina abilità a implementare programmi efficienti e affidabili, un esame etico preventivo riguardo ai suoi possibili utilizzi.
Non è più sufficiente dare per scontato che un dispositivo tecnologico possa essere usato per il bene o, purtroppo, per il male.
Gli ingegneri hanno costruito, in molti modi, il mondo moderno e aiutato a migliorare la vita di molte persone. Di ciò siamo giustamente orgogliosi. Inoltre, solo una piccola parte di noi opera in attività legate agli armamenti o ad algoritmi che non rispettano la privacy. Ad ogni modo, noi siamo parte e un gruppo specifico della modernità industriale con tutta la sua potenzialità, i suoi svantaggi e i suoi difetti, e dunque contribuiamo sia alla sofferenza che allo sviluppo dell’umanità… Sarà un bel giorno per la nostra professione quando inizieremo a formare più ingegneri che, oltre ad essere molto intelligenti …, hanno la volontà e la capacità intellettuale di impegnarsi con le questioni più grandi quali l’etica, la politica e le ramificazioni sociali delle loro invenzioni (El-Zein, 2013).
Ad ogni modo, per avere un quadro più preciso della tematica dovremmo non appiattirci troppo su un qualche evento ora particolarmente illuminato dai media. In effetti, un recente studio ci dice che ben il 60% del traffico dati è di origine not-human: la rete pullula di algoritmi che lavorano per generare/affrontare ogni tipo di problema provando anche a ripristinare un qualche principio di ordine o utilità. Ad esempio, rimuovendo i commenti o le recensioni postate ad arte per alterare i tentativi di misurare realmente, tramite feedback personali, i servizi forniti o alimentare tendenziosamente le discussioni.
Gli algoritmi stanno diventando ancora più importanti nella società e si applicano per tutto. Dai motori di ricerca online che intervengono a livello di personalizzazione, discriminazione, diffamazione e censura, al come sono valutati gli insegnanti, lavora il mercato o stanno funzionando le campagne politiche, fino al riscontro automatizzato su come le forze dell’ordine trattano, in relazione al loro status, gli immigrati. Guidati da un enorme mole di dati, gli algoritmi sono i nuovi e potenti intermediari nella società, sia a livello di corporation che statale. Come noi, essi hanno delle preferenze e fanno errori. Ma sono opachi, nascondendo i loro segreti dietro strati di complessità (Diakopoulous, 2013).
Per non fermarsi e accontentarsi dei report sulla trasparenza, in cui i vari provider di contenuti o di servizi di rete illustrano le richieste ricevute da privati e autorità per “regolamentare” in qualche modo i loro servizi, il suggerimento è di attivare una pressione per dover giustificare (accountability) il funzionamento dell’algoritmo stando attenti a decifrarne il comportamento (reverse engineering).
Gli algoritmi sono essenzialmente una scatola nera che espongono input e output nascondendo qualunque loro organo interno. Non è possibile vedere direttamente cosa accade all’interno, ma variando gli input in maniera sufficiente e ponendo attenzione agli output è possibile mettere insieme degli indizi su come l’algoritmo si comporta trasformandoli. La scatola nera inizia a divulgare alcuni segreti … dato il crescente potere che gli algoritmi hanno nella società è vitale continuare a sviluppare, codificare e insegnare metodi più formalizzati per dover rispondere responsabilmente dell’algoritmo (Diakopoulous, 2013).
Un esempio particolare e indicativo del modo in cui ci misceliamo con i software culturali sta interessando il nostro intrattenimento video. Il noto analista e storico dei media Tim Wu, che insegna alla Columbia Law School, si è soffermato ultimamente sui cambiamenti del consumo televisivo e cinematografico che è in corso negli Stati Uniti e, per la verità, un po’ ovunque nel mondo dopo l’avvento degli accessi broadband.
In particolare, i servizi di streaming di contenuti video fruibili in maniera illimitata da internet tramite la sottoscrizione di un abbonamento mensile ha rafforzato la tendenza a costruirsi un palinsesto altamente personalizzato, che può contare su una quantità abnorme di ogni genere di contenuti video, ora anche originali perché prodotti direttamente dal provider ritagliandoli per i gusti del proprio pubblico.
Nonostante la televisione continui a registrare alti livelli di ascolto, il modo di organizzare e offrire i servizi di intrattenimento da parte di questi provider — Netflix , soprattutto — sta segnando un cambio di passo epocale nei consumi culturali americani. Tra i punti più controversi vi è la perdita di quel vasto senso di comunità tramite cui i riti del consumo di massa ci univano.
Tutto ciò non può essere solo causa di disappunto. Una perdita di comunità può diventare il guadagno di un’altra poiché, nel momento in cui la cultura di massa affievolisce, si creano aperture per un insieme di persone che vogliono riunirsi in altri modi. Quando si incontra qualcuno con le stesse particolari passioni e sensibilità il senso di connessione può essere profondo. Piccole comunità di fan, forgiati da prospettive condivise, offrono un senso più genuino di appartenenza rispetto alla identità nazionale nate da circostanze geografiche (Wu, 2013).
L’analisi di Netflix — l’azienda americana sinonimo in rete del Video On Demand e a cui fanno capo attualmente circa 40 milioni di abbonati (31 milioni negli USA) — lascia meravigliato Wu per l’abilità della stessa di cavalcare con successo l’onda, spingendo sui tasti giusti del medium internet. Le ultime mosse riguardo alla produzione di contenuti originali — essa investe centinaia di milioni di dollari a fronte di un profitto di soli 17 milioni nel 2012 — sono solo la messa in opera dei suoi obiettivi iniziali. I fondatori, persone appassionate ed esperte di cinema, vogliono promuovere un’azienda high-tech i cui prodotti sono i contenuti video ricercati e/o fatti scoprire ai suoi abbonati, di cui segue e sollecita anche le singole ideosincrasie.
Se la moderna cultura popolare degli Stati Uniti è stata costruita su un pilastro centrale dell’intrattenimento tradizionale affiancata da sub-culture più piccole, ciò che la sta sostituendo è una infrastruttura molto diversa, che comprende isole di appassionati (fandom) (Wu, 2013).
Per Netflix, implementare una poderosa e flessibile infrastruttura globale di streaming è stato solo il primo passo abilitante, tra l’altro seguito a ruota da quasi tutti gli altri grandi media. Ma essa nel frattempo si è attrezzata per leggere, come dice qualcuno, “nell’anima dell’America” mettendo in campo una sorta di reverse engineering della produzione hollywoodiana.
Se utilizzate Netflix probabilmente vi sarete fatte delle domande sui generi che vi suggerisce. Alcuni sembrano così specifici da essere assurdi. Documentari emozionali combattere-il-sistema (Emotional Fight-the-System Documentaries)? Esempi d’epoca relativa a famiglie reali basate su storie accadute (Period Pieces About Royalty Based on Real Life)? Storie sataniche estere degli anni ’80 (Foreign Satanic Stories from the 1980s)? Se Netflix riesce a mostrare parti così dettagliate di film ad ogni utente, e ne hanno 40 milioni, quanto ampio deve essere il loro set di “generi personalizzati” per descrivere l’intero universo di Hollywood? La domanda è diventata affascinante nel momento in cui ho compreso che avrei potuto cogliere ogni microgenere che l’algoritmo di Netflix abbia mai creato. Attraverso una combinazione di olio di gomito e di richieste a ritmo di spam, abbiamo scoperto che Netflix non possiede diverse centinaia di generi, o anche diverse migliaia, ma ben 76.897 modi unici per descrivere i generi dei film (Madrigal, 2014).
La conclusione è che Netflix ha catalogato e descritto ogni film e programma tv dotandosi di un data base poderoso unico con cui si aiuta a generare, incrociando i dati estratti dalle modalità e abitudini d’uso degli abbonati, categorie altamente personalizzate. Intervistato a proposito, l’ideatore di questa opera di de-costruzione filmica, Todd Yellin, ha spiegato come allo scopo sono state impiegate molte persone, addestrate a descrivere e valutare i contenuti associandovi metadati di ogni genere, compresi gli elementi narrativi e le loro svolte conclusive.
Essi hanno catturato dozzine di differenti attributi filmici. Hanno anche dato dei punteggi allo status morale dei personaggi. Nel momento in cui queste descrizioni sono combinate con le abitudini di uso di milioni di persone, per Netflix esse diventano un vantaggio competitivo. L’obiettivo principale dell’azienda è di guadagnare e mantenere abbonati. I generi loro mostrati fanno parte di questa strategia. “Gli abbonati si relazionano così bene con questi generi che misuriamo un aumento nel mantenimento dei clienti mettendo le categorie maggiormente personalizzate più in alto nella pagina … Più Netflix mostra di conoscervi, più cresce la probabilità di rimanere dalle sue parti. Ed ora, essi hanno un micidiale vantaggio nello sforzo di produrre propri contenuti detenendo il data base delle preferenze cinematografiche degli americani. I dati non gli spiegano come fare un programma tv ma gli dicono che cosa dovrebbe essere creato. Quando hanno prodotto una serie tv come House of Cards non hanno dovuto indovinare ciò che le persone volevano” (Madrigal, 2014).
 Avere la disponibilità programmatica di tali dati nel loro continuo rigenerarsi tramite l’interazione degli usi può significare poter estrapolare velocemente informazioni utili per un qualche altro scopo — accanto e sotto ci sono alcuni esempi elaborati velocemente da Madrigal con i dati estratti nell’analisi.
Avere la disponibilità programmatica di tali dati nel loro continuo rigenerarsi tramite l’interazione degli usi può significare poter estrapolare velocemente informazioni utili per un qualche altro scopo — accanto e sotto ci sono alcuni esempi elaborati velocemente da Madrigal con i dati estratti nell’analisi.
In conclusione, è in corso, ormai quotidianamente, un potente processo  di compenetrazione e adattamento di sistemi umani e macchinici, di cui si prova a risolvere o gestire le complesse problematiche, avanzando con mezzi che aggiungono a loro volta complessità e, conseguentemente, possibilità o risultati spesso non immediatamente immaginabili.
di compenetrazione e adattamento di sistemi umani e macchinici, di cui si prova a risolvere o gestire le complesse problematiche, avanzando con mezzi che aggiungono a loro volta complessità e, conseguentemente, possibilità o risultati spesso non immediatamente immaginabili.
Rispondendo a una domanda su un risultato prodotto dall’algoritmo che sembrerebbe molto contradditorio rispetto alla comune percezione, Yellin  ammette che aggiungere complessità significa anche navigare in un’indeterminatezza che potrebbe comunque anche risultare fruttuosa (serendipity) a livello di soluzioni prodotte. Usando le sue parole “qualche volta le definiamo bachi [ma] altre volte feature”.
ammette che aggiungere complessità significa anche navigare in un’indeterminatezza che potrebbe comunque anche risultare fruttuosa (serendipity) a livello di soluzioni prodotte. Usando le sue parole “qualche volta le definiamo bachi [ma] altre volte feature”.
Tuttavia, alla luce di quanto precedentemente osservato in termini di accountability degli algoritmi, e pensando a tutti i meccanismi similari che sono o si stanno mettendo in campo, sarebbe importante che sul merito delle soluzioni possano essere coinvolti tutti i co-partecipanti cosicché essi possano valutarne in maniera ampia e più consapevole storture e benefici.
Riferimenti
Diakopoulos, N., 2013, “Rage Against the Algorithms“, The Atlantic, 3/10.
El-Zein, A., 2013, “As engineers, we must consider the ethical implications of our work”, The Guardian, 3/12.
Jobin, A., 2013, “Google’s autocompletion: algorithms, stereotypes and accountability“, sociostrategy.com.
Madrigal, A. C., 2014, “How Netflix Reverse Engineered Hollywood”, The Atlantic.com, 2/1, <>
“Report: Bot traffic is up to 61.5% of all website traffic”, incapsula.com, 9/12/2013.
Wu, T., 2013, “Netflix’s war on mass culture“, New Republic.com, 3/12.